This is a very common interview questions for product and FANG companies. Even though the problem statement appears to be too simple the actual implementation has some architectural challenges.
Why do we need URL shortening?
URL shortening service or a webservice is used to create shorter/terse aliases for long URLs. We call these shortened aliases as “short links.” Users are redirected to the original URL when they hit these short links.
Short links save a lot of space when displayed, messaged, printed or tweeted or for any other purpose.
Additionally, users are less likely to mistype shorter URLs and thereby avoiding lot of 404’s.
For example, if we shorten the below page through TinyURL:
https://teachyourselfcoding.com/articles/full-stack-master-class-vanilla-javascript-react-angular/we get
https://tinyurl.com/y5vrhslnA shortened URL is a combination of
- Numbers (0-9)
- Characters (a-Z)
- And usually length around 7 to 8 characters
Functional Requirements
Our URL shortening system should meet the following functional requirements.
- Given a URL, the service should generate a shorter and unique URL from it. This is called a short link.
- When users access a short link, the service should redirect them to the original link.
- Links can expire after a standard default expiry timespan. Users may optionally be able to specify expiry time.
- Users can optionally be able to create a custom short link for their URL (Note: The custom short link should be unique).
Non-Functional Requirements
Our URL shortening service should also adhere to the below NFR’s.
- URL redirection should happen with minimal latency.
- The system should be highly available. If the service is down, all the URL redirections will fail.
- URL redirection should happen in real time.
Analytics requirements
Apart from the functional and NFR’s the below analytical requirements are nice to have features.
- How many times a redirection happened?
- REST API end point.
- How many failed redirection happened?
Capacity Planning
The critical factor to consider in this kind of application/service is that the reads will be more than the writes.
We can assume the ratio of read to write as 100: 1. (Or depending on your context you can change this)
Let’s start small. Assume we will have 500 million new URL shortening request per month, with 100:1 read/write ratio, we can expect 50B redirections.
100 * 500M => 50BLet’s also calculate the Queries Per Second (QPS) for our new system.New URL Shortening requests per second
New URL Shortening requests per second
500M / (30 days * 24 hours * 3600 seconds) = ~200 URLs/second
So, URL redirections per second will be (100:1 read/write ratio)
100 * 200 URLs/s = 20K/s
Storage Estimates
Let’s assume we store every URL shortening request for 10 years. Since we have 500M new URLs every month, the total number of objects we expect to store will be
500 million * 10 years * 12 months = 60 billion
Let’s assume that each stored object will be approximately 500 bytes (just a rough estimate).
We will need 30TB of total storage.
60 billion * 500 bytes = 30 TB
Bandwidth Estimates
Bandwidth is (network bandwidth) is the term used to denote the amount of data transfer(data size) in a period of 1 second.
Data transfer will included, incoming as well as outgoing data.
- Incoming data is the amount of data transferred to the server (same as file upload type)
- Outgoing data is the amount of data returned from the server to the client (like downloading).
We expect 200 new URLs per second. So a total incoming data for our service will be 100KB per second.
200 * 500 bytes = 100 KB/s
For read requests, since we expect ~20K URL redirections every second, total outgoing data for our service will be 10MB per second.
20K * 500 bytes = ~10 MB/s
Cache (Memory Estimation)
To optimize performance and reduce the DB round trip caching URL’s will be an efficient solution.
Here’s let’s follow the, Pareto principle, aka 80:20 rule, i.e. 20% of the short links generate 80% of the system traffic.
So, since we have a total of 20K URLs / s (or 20K requests/ s), then , 1 day will have:
20K * 3600 seconds * 24 hours = 1.7B request / day
To cache 20% of these requests, we will need
0.2 * 1.7B * 500 bytes = 170GB memory
NOTE: Due to duplicate requests, our actual memory usage will be lesser thatn 170GB.
Caching considerations
- Built in cache of the backend server vs Redis or Memcached
- Cache invalidation strategy
System Size (ballpark)
Since our system has 500M urls in a month and has a read:write ratio of 100:1, the below will be the system specifications.
- 200 URLs generated every second
- 20K requests / per second
- 100 KB/s incoming data
- 10MB/s outgoing data
- Disk capacity for 10 years: 30 TB
- Memory Capacity for cache: 170 GB
Database Design
Based on the analysis done so far the below will be our database requirements.
- Billions of records needs to be saved
- The system has a high read rate
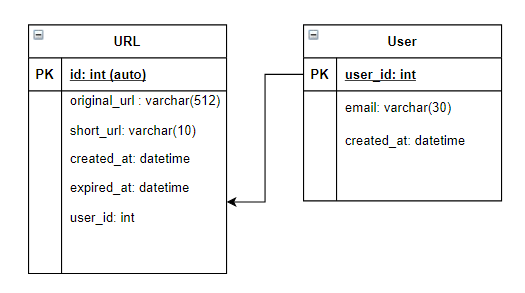
Database Schema:
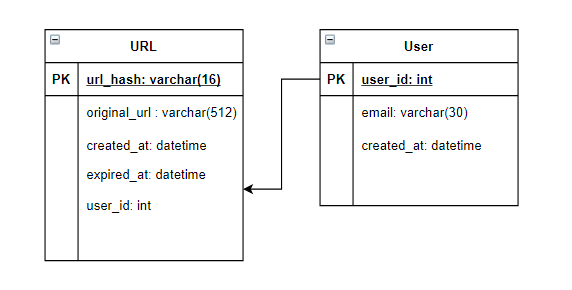
Either SQL or NoSQL will work for this solution (But a nosql will be much better)
You can also use the auto increment ID feature of database (for base62 encoding approach as shown in the algorithms section)
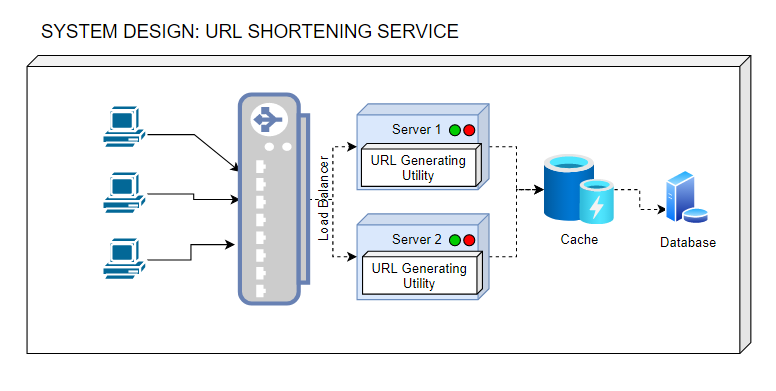
Load Balancer (LB)
As scale is important adding load balancer will significantly improve the end user experience. Though load balancing can be applied at may places, here starting to load balance between the clients and application servers will be sufficient. Then based on estimates of scale additionally load balancing can be applied at
Security and Permissions
If the system has the requirements to create private URL’s then these factors need to be taken into consideration to compute storage.
Basic System Design and Algorithm
Shortening Techniques/Algorithms
There are multiple approaches to shorten the URL’s and few are outlined below.
- Base 62 encoded string
- Hashing function
- Integer based sequence
Base62Encoding or use a Bijective function.
In mathematics, a bijection, bijective function, one-to-one correspondence, or invertible function, is a function between the elements of two sets, where each element of one set is paired with exactly one element of the other set, and each element of the other set is paired with exactly one element of the first set. There are no unpaired elements. In mathematical terms, a bijective function f: X → Y is a one-to-one (injective) and onto (surjective) mapping of a set X to a set Y.[1][2] The term one-to-one correspondence must not be confused with one-to-one function (an injective function; see figures).
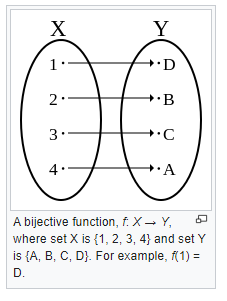
Read more here https://en.wikipedia.org/wiki/Bijection
Here is is a one to one mapping between base 10 (decimal) to base 62.
Base62 uses 62 possible ASCII letters, 0 – 9, a – z and A – Z, therefore it is often used to represent large numbers in short length of string. Mainly it has two advantages:
- A shorter number representation in base62 yields a smaller risk of error entered by human and the number can be typed in faster.
- The second advantage is that it can be used in a more restricted application where the length for URL or name, identify is limited.
Again why 62 possible characters? Check the calculations below for base 62
A-Z = 26 characters
a-z = 26 characters
0-9 = 10 characters
Which totals to 62 characters.
The JavaScript code to convert to and from decimal(1) to base 62 and vice versa.
const BASE_62_VALUES = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ";
// convert from decimal to base (default 62)
function to_base(num, base = 62) {
if (num === 0 ) return BASE_62_VALUES[0]
result = []
while (num > 0) {
r = num % base
console.log(r);
result.unshift(BASE_62_VALUES[r])
num = Math.floor(num / base)
}
return result.join("");
}
// Convert to decimal from base (default 62) encoded string
function from_base(value, base = 62) {
base_10_num = 0
digit = 0
value.split('').reverse().forEach(char => {
num = BASE_62_VALUES.indexOf(char)
base_10_num += num * Math.pow(base, digit)
digit += 1
})
return base_10_num
}
console.log(`1: ${to_base(1)}`); // => 1
console.log(`decode: ${from_base(to_base(1))}`); // => 1
console.log(`98: ${to_base(98)}`); // => 1A
console.log(`decode: ${from_base(to_base(98))}`); // => 98
Code can be tested here https://jsbin.com/nohujes/edit?js,console,output
Now once we have this basic conversion function we can use the DB auto increment entity ID for the long URL and save the shortened form. (You can take a different approach as well)
How Base 62 encoding works?
More details here https://en.wikipedia.org/wiki/Base62
- Setup up the encoding characters
- “0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ”;
- NOTE: Here character at index 0 is ‘0’ and character at index 61 is ‘Z’
- Create empty array or hash
- While the input number is greater than 0
- Take the base 10 input and modulus it with 62 and store the result into a variable. The resultant value will always be between 0 and 61 (inclusive)
- Get the character at that position using the variable defined above.
- Reset the input with the floor value of the input divided by the base.
- Convert the resultant array/hash as string
Assume our short service URL is https://shrt.ly
Steps to create short links
- User visits https://shrt.ly
- The user enters the long URL and submit the form
- In the backend the service will create a db entry for this long url
- It then uses the entity ID and crates a short url using the base 62 function.
- The shortened URL will be returned back to the user.
Steps to navigate the original URl using short link
- User visits a short url page for e.g. https://shrt.ly/1a
- The server decodes the short url to get the id and uses the ID to fetch the long URL.
- The server redirects the user using the long URL.
NOTE: The URL routing/matching part of your service should be optimized as that can result in slower user responses.
Hash function (like MD5 or SHA-2 etc)
<TODO>
Assignment
Create a website/webservice for URL shortening using the above algorithm.